Ce projet s'intègre dans le cadre de mon stage de M1 au sein du GReD qui avait pour but de simplifier l'usage de la solution de Deep Learning Biom3d pour les biologiste. Le projet fait suite à une étude montrant le manque de reproductibilité des méthodes de deep learning en imagerie biologique et s'appuie sur Biom3d, dont l'article est en cours de publication.
Développement :
Le travail s'est articulé autour de quatre axes.
Maintenance de Biom3d. En analysant le dépôt via SonarQube, j'ai corrigé de nombreux défauts de code (variables inutilisées, code commenté, moteur d'aléatoire déprécié de numpy) et rendu les messages d'erreur plus explicites. J'ai également testé les dix modèles fournis dans la publication originale et constaté que quatre étaient incompatibles avec la version courante. Après analyse des causes, les modèles ont été corrigés et remis à disposition sur le dépôt public. J'ai également contribué aux réponses aux reviewers de l'article scientifique proposant Biom3d, en cours de publication,et serai crédité en tant que co-auteur lors de sa parution.. De plus, pour faciliter le travail des futurs dévelopeurs, j'ai grandement étendu la documentation.
Export vers Bio Image Zoo et DeepImageJ. DeepImageJ étant en Java et Biom3d en Python, il fallait un format intermédiaire : j'ai choisi TorchScript. Cela impliquait de rendre compatible l'ensemble du pipeline de prédiction, ce qui s'est avéré particulièrement complexe : la bibliothèque torchio utilisée pour le découpage en patches, le chargement par batch, la parallélisation et l'agrégation repose massivement sur numpy, incompatible TorchScript. J'ai donc réimplémenté from scratch un GridSampler et un GridAggregator compatibles, validés par comparaison bit-à-bit avec la version originale. J'ai également réimplémenté les filtres de post-traitement (keep_big_only, keep_biggest) qui dépendaient de skimage. L'ensemble est encapsulé dans un nouveau module ModelExport dont héritent les modèles exportables.
Intégration dans Bacmman. Bacmman utilisant Docker pour isoler ses modèles de deep learning, l'intégration était conceptuellement plus simple. J'ai créé un plugin Java implémentant l'interface DockerDLTrainer ainsi qu'une image Docker Biom3d compatible (ce qui a nécessité de résoudre des problèmes de dépendances PyTorch/CUDA). L'entraînement est fonctionnel sous forme de MVP ; les prédictions sont en cours d'intégration, et bien plus difficile à intégrer dû au système de pipeline de Bacmman.
Déploiement. J'ai également créé un environement python embarqué à l'aide de Conda ainsi que des scripts wrapper pour créer des éxécutables Windows et MacOs, facilitant grandement l'instalation. J'ai également développé une CI/CD github pour créer automatiquement ces éxécutables et les images Docker.
Conclusion :
Ce stage m'a confronté à des problèmes techniques variés et concrets : interopérabilité entre langages, contraintes du compilateur TorchScript, gestion des dépendances GPU dans Docker, et maintenance d'une codebase open source existante. La principale difficulté est venue d'une documentation souvent incomplète ou contradictoire (Bio Image Zoo notamment), ce qui m'a appris à naviguer dans du code source tiers pour compenser. La version embarquée est aujourd'hui utilisée au laboratoire, ce qui constitue un retour concret et satisfaisant sur le travail effectué.
Ce projet s'intégrait dans le contexte de nos cours de middleware, afin de mettre en pratique les principes vus en cours et avoir de l'expérience sur un langage non utilisé auparavant (Go).
Développement :
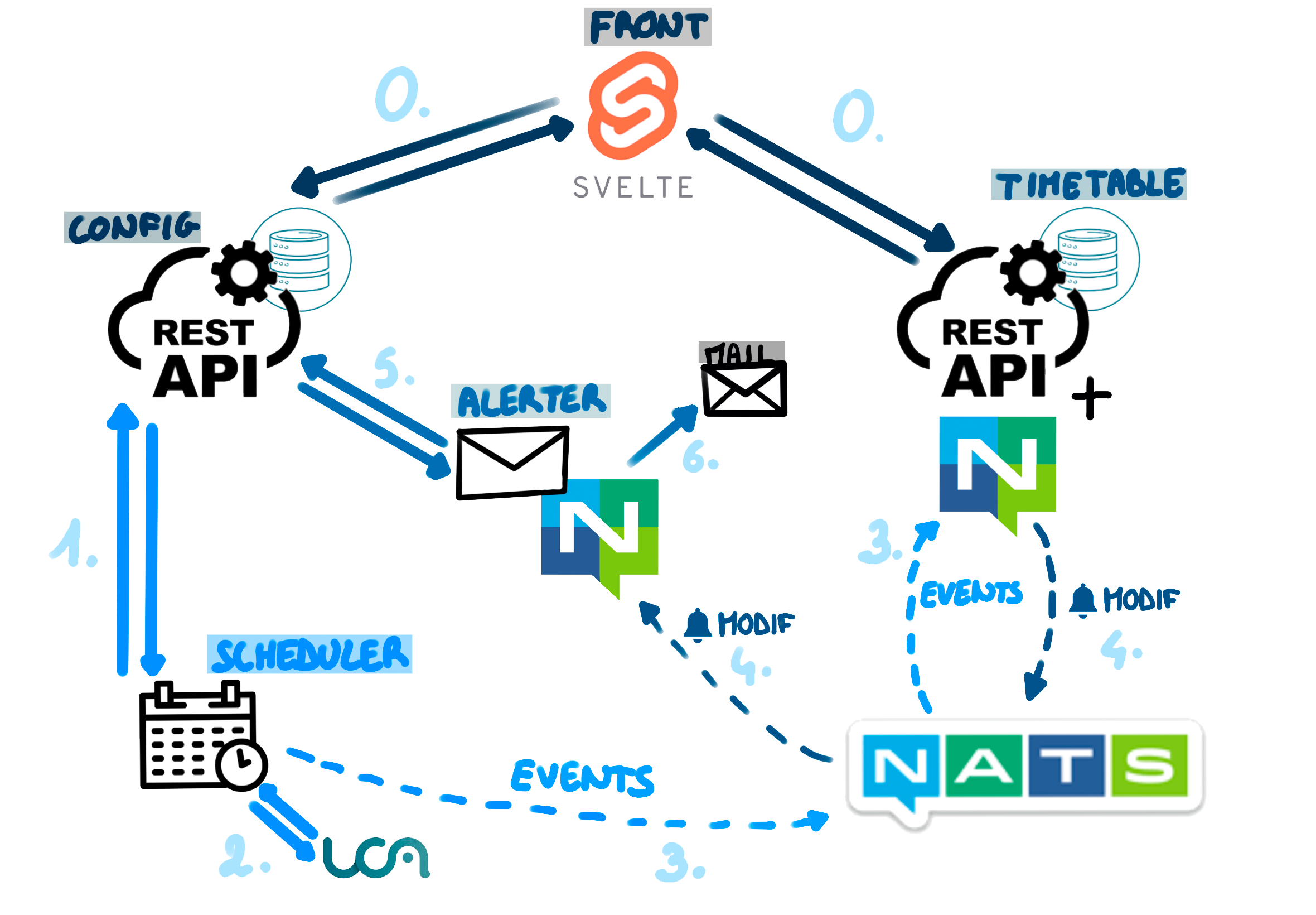
Le but était de créer différentes API REST et middlewares afin de reproduire le schéma suivant :
Schema des différents middlewares
Le front était fourni, et j’étais assigné à l'API Config. Le but de cette API était de stocker les emplois du temps suivis par l'utilisateur ainsi qu’à quelle adresse mail envoyer une alerte en cas de changement.
Je suis parti d'un projet Go fourni qui définissait déjà la méthode GET et ai ensuite développé les verbes demandés : GET, POST, PUT, DELETE. De plus, j'ai pris la liberté d'ajouter PATCH, OPTIONS et HEAD. J'ai également écrit la documentation avec Swagger. Cette API est donc au niveau 2 de l'échelle de maturité de Richardson.
Conclusion :
Ce projet m’a permis d'apprendre les bases du Go et d'écrire une API REST complète, ce que je compte refaire dans certains projets personnels.
DevOps : Déploiement continu d'une application
Date du projet : Octobre 2024, durant mon M1
Durée du projet : 2 mois
Contexte du projet :
Ce projet s'intégrait dans le contexte de nos cours de DevOps. Nous avons d'abord fait plusieurs TP afin de nous familiariser avec les différents outils (Terraform, Ansible, Docker, Prometheus/Grafana, GitLab CI, Vault), puis en autonomie nous devions créer une infrastructure pour déployer de façon continue plusieurs applications.
Développement :
Le déploiement se faisait sur une machine virtuelle sur OpenStack. Sur cette machine, je devais déployer plusieurs services :
Un service WordPress
Un service Nextcloud
Une base de données MariaDB (qui contient deux sous-bases de données et leurs utilisateurs pour les deux premiers services)
Une application écrite en Go (fournie sur un dépôt Git), sur laquelle je devais inclure une CI
Exposer les services précédents
La contrainte principale était que nous n’avions droit qu’à une seule machine virtuelle.
Pour créer la machine virtuelle, j'ai créé un script Ansible qui permet de la paramétrer. Ce script créait la VM, installait les dépendances et copiait les scripts permettant de déployer les autres services. Un deuxième script Ansible permettait de créer les enregistrements OVH pour les 3 services (les noms de domaine étaient fournis).
Pour déployer les services, j'ai choisi d'utiliser Docker, et je les déployais tous en même temps avec un Docker Compose, sur le même réseau. Le premier service était MariaDB. Pour créer les utilisateurs, je devais définir leur mot de passe. Pour des raisons de sécurité, ces mots de passe étaient stockés sur Vault et récupérés par un script Bash. Les conteneurs des 3 applications n'ont pas posé de problèmes. La difficulté venait de l'exposition : pour cela, j'ai utilisé un conteneur Traefik qui servait de point d'entrée Internet, n'acceptant que les connexions HTTPS et redirigeant toutes les HTTP sur leur équivalent HTTPS. Pour assurer le monitoring, j'ai utilisé un conteneur Prometheus et un conteneur Grafana. Mais comme les informations apportées par Prometheus concernaient principalement la VM et non les autres conteneurs, j'ai rajouté un conteneur cAdvisor. Cependant, dû à un manque de temps, je n'ai pas pu faire de dashboard Grafana persistant.
La CI était la partie la plus complexe. Elle devait installer les dépendances nécessaires, compiler le code, créer un conteneur et le transmettre à la VM. La conteneurisation se faisait avec un Dockerfile. La partie la plus complexe était la transmission : GitLab n'acceptait que des connexions en IPv4, et la VM était uniquement en IPv6 (pour des raisons de coût). J'ai d'abord cherché à utiliser un jumphost, mais j'ai ensuite préféré que la CI pousse l'image Docker sur Docker Hub. Cela permettait un meilleur versionnage de l'application.
Conclusion :
Ce projet était de loin le plus complexe, mais aussi très proche de ce qui serait fait en entreprise, et donc particulièrement formateur. Je n'ai pas pu faire tout ce dont j'avais envie, mais j’ai réussi à faire un rendu satisfaisant.
Ce projet s'intégrait dans le contexte de nos cours de génie logiciel. Le but était de se familiariser avec les frameworks de test (JUnit) et les méthodes de refactoring. Pour cela, nous avons fait un Golden Master sur un code volontairement mal écrit.
Développement :
Le projet a été séparé en 3 étapes :
Écriture de tests : cette partie était relativement courte et la difficulté venait de la complexité du code.
Refactoring : cette partie était la plus longue et la plus complexe, car je devais déterminer ce qui devait être changé (une bonne partie du code) et trouver les pratiques et patterns les plus adaptés.
Ajouts : cette partie était facile, notamment car le refactoring les facilitait.
Tout au long de ce projet, j'ai utilisé Git pour versionner mon travail.
Conclusion :
Ce projet m'a permis de refaire des tests et de m'améliorer dans le domaine, ainsi que de maintenir mes compétences en Java et Git, ainsi que ma maîtrise des concepts de génie logiciel.
Ce projet s'inscrivait dans une matière visant à appréhender la simulation stochastique, il faisait suite à la simulation de pi via la méthode de Monte-Carlo. Le but était de créer une simulation de population de lapin en étant libre de nos choix. Nous avons fait le choix de faire une simulation complexe en modélisant de façon simple l'écosystème.
Développement :
Pour simuler un écosystème, nous avons fait le choix de quatre paramètres, la nourriture, les prédateurs, les maladies et le climat. Le climat est le paramètre qui affecte le plus la simulation car c'est celui qui modifie les autres. La nourriture, les prédateurs et une maladie sont des tableaux avec des taux de mortalité dépendant de l'indice, les maladies sont un tableau de maladie ainsi que leur chance d'apparition ainsi que deux tableaux de maladie dépendant de la densité de population, finalement le climat est séparé en mois avec pour chaque mois, une valeur d'humidité (une parmi trois) et une valeur de température (une parmi trois).
Il y a également des paramètres liés au lapin en eux-mêmes comme leur sexe, leur capacité à se reproduire et leur âge.
On effectue ensuite la simulation mois par mois en calculant la mortalité, puis la reproduction avant de mettre à jour les paramètres avant de passer au mois suivant. Une fois les taux calculés, on les applique sur chaque lapin de la population. Certains paramètres fonctionnent de manière constante, par exemple si le mois est humide, alors les lapereaux auront une mortalité supplémentaire fixe à cause de l'inondation des terrier.
Les résultats sont ensuite stockés dans un fichier résumant chaque mois. Pour lancer une simulation, il faut un fichier avec une population de base de lapin ainsi qu'un fichier venant définir les paramètre environnementaux. Plusieurs jeux de données ont ensuite été construit et des statistiques ont été faites sur les résultats donnés.
La simulation de départ était développée en C, mais suite à une perte de temps sur le développement de structure et de gestion de mémoire il a été transcris en java. D'autres raisons ont justifiées ce choix : la gestion du parallélisme innée de Java ainsi qu'un manque de pratique de Java pouvant être résolu avec ce projet.
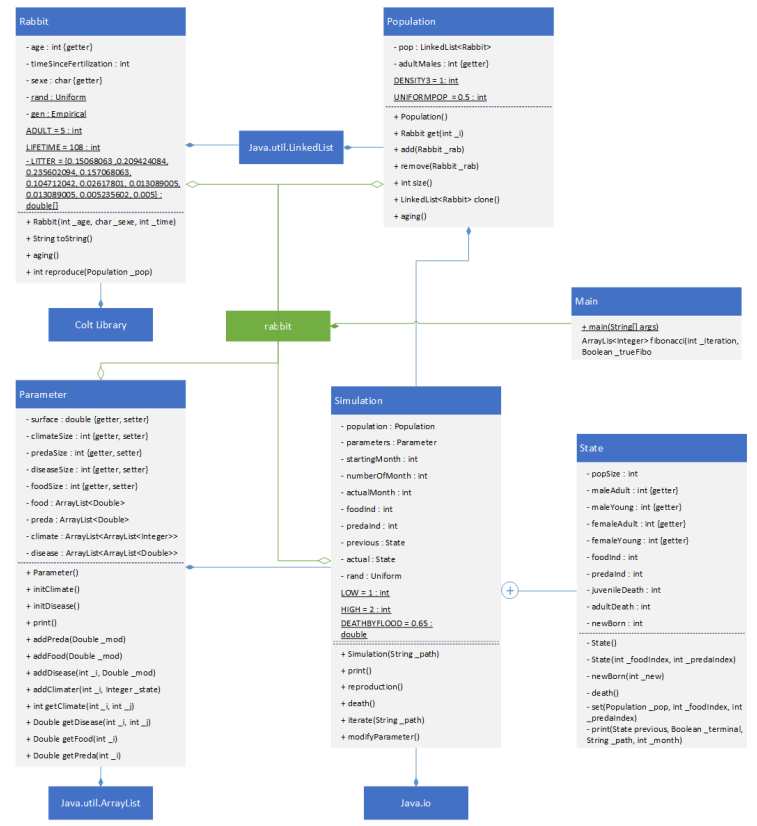
Schema uml de l'architecture du code
Conclusion :
Deux conclusions peuvent être faites en ce qui concerne les choix d'implémentation : les concepts objets sont peu respectés (dû à une transcription plutôt qu'un refactoring), une erreur fatale s'est glissé dans le code, le générateur aléatoire est initialisé dans la simulation ce qui fait que lancer une simulation en boucle afin de produire différents résultats à des fins statistiques produiront toujours le même résultat.
La construction de jeux de données a été fait par intuition et tests, là où en théorie ils devraient être construit à partir de nombreux statistiques. Il est donc possible que les opérations définies sur ces jeux de données ne marche pas ou mal sur de vrai donné, ce qui rendra cette simulation caduque. De même pour certaine constante.
En revanche, la modélisation d'un système complexe dans un système bien plus simple a été un exercice très intéressant et instructif. De même nous avons pu mieux maîtriser certains objets java (comme les listes) et pu augmenter nos connaissances en biologie concernant les lapins (bien que ce ne soit pas le but du projet).
Ce projet s'inscrivait dans la matière web, suivant un projet de frontend (que je ne présente pas ici car peu intéressant et ce site est tout autant représentatif). Le but était de nous initier au backend en utilisant java spark et en évitant les framework existant afin de mieux comprendre le fonctionnement. Le choix du thème Pokémon était pour nous permettre d'avoir accès au PokeAPI afin de pouvoir nous concentrer sur le backend. Ce projet à également le premier où nous avons utilisé gradle.
Le but est de répondre au cahier des charges suivant :
Un utilisateur peut créer un compte et se connecter.
Un utilisateur peut échanger des pokémons avec les autres.
Un utilisateur peut faire gagner 1 niveau a un Pokémon (qu'il soit le sien ou pas) 5 fois par jour.
Un utilisateur reçoit un Pokémon à sa première connexion journalière.
Nous devions également utiliser le modèle Model View Controller, ainsi que créer et gérer la base de donné nécessaire à notre application. De plus, nous devions utiliser la technologie freemarker pour générer les pages web.
Développement :
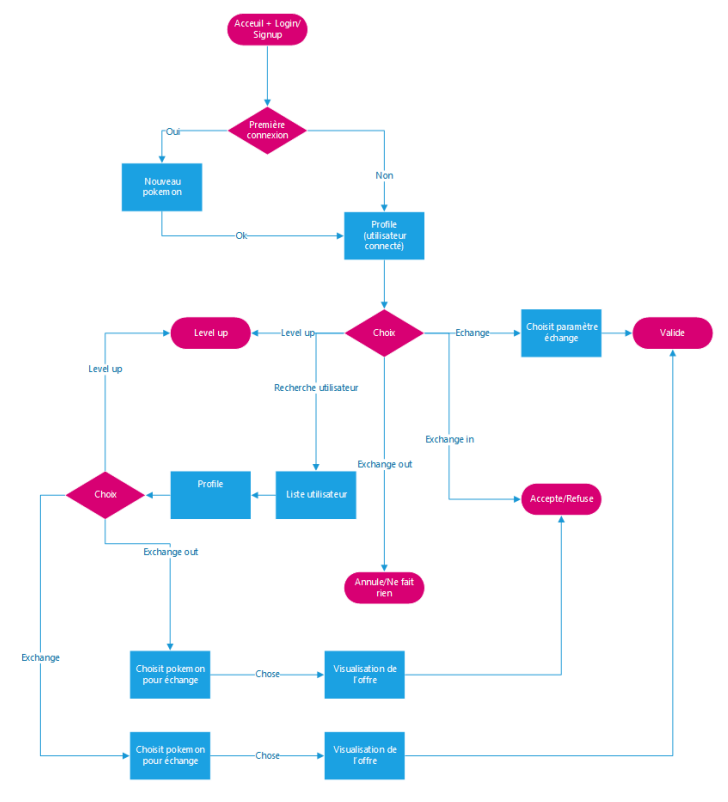
Nous avons défini le flow suivant pour notre application :
Diagramme de flow
Chaque utilisateur à donc accès a 6 pages :
Son profil.
Le profil d'un autre utilisateur.
La page d'un Pokémon.
Sa page d'échanges sortants (ceux qu'il propose).
Sa page d'échanges entrants (les demandes qu'il reçoit).
La page d'échanges sortants d'un autre utilisateur.
Ainsi que d'autre page intermédiaire comme celle qui permettent de créer un échange ou la page donnant un Pokémon lors de la première connexion.
Les template des pages ont été faits avec freemarker et utilise des pages css statiques, elles ne contiennent que le strict minimum car le but n'était pas de faire un beau site web mais de se concentrer sur le backend.
Conclusion :
Il y a plusieurs critiques adressables à ce projet. Premièrement, le Java est parfois mal utilisé notamment avec des cas particuliers pouvant être remplacés par des exceptions. De plus, la sécurité des mots de passe n'était pas optimal car dans la même base de données que l'application, le salt compris. On peut ajouter à cela que le site est en http non sécurisé dû au fait que l'auto-certification était pour nous un concept inconnu à ce moment.
La base de données est également pas une base de données à utiliser en production, c'est avant tout une base de données de développement (notamment sur les contraintes réduites au minimum).
Également, il reste un bug dans l'application où un joueur peut échanger avec lui-même, causant la suppression de tous les échanges existants pour les pokémon impliqués (car dans le cas d'un échange avec un autre joueur il est logique de supprimer les autres échanges car devenus non pertinents).
Ce projet était dans le cadre de la matière compilation, soit théorie des langages avancée, où il faisait partie de l'évaluation. Le but était de créer un compilateur vers la machine virtuelle MVAP (car possédant des instructions simples).
Nous devions utiliser Antlr afin de créer ce compilateur.
Développement :
Il y a peu à dire sur l'implémentation et les choix car il s'agit juste de transcrire la grammaire fournie dans le sujet. Pour l'implémentation des outils utilisé par le langage (calcul du pgcd et ppcm) ou des variables utilisées pour les boucles, nous avons alloué un espace mémoire au début de la pile (car c'est le seul endroit connu dès la compilation). Également, les variables doivent être déclarées au début du programme car elles sont aussi ajoutées au début de la pile.
Plusieurs ajouts ont été faits par rapport au sujet, premièrement nous avons ajouté les commentaires avec la même syntaxe qu'en C. En plus de la boucle do while demandée dans le sujet nous avons ajouté la boucle while ainsi qu'un opérateur d'incrémentation et de décrémentation sur les variables entière, permettant de créer la boucle for.
Conclusion :
Une des fonctionnalités que nous avons essayé d'implémenter ne fonctionne pas. En effet, nous voulions ajouter que le compilateur ajoute l'instruction de vider la pile créée dans le programme. En revanche, l'aspect "non déterministe" des conditions et boucles empêchaient le calcul de la taille de la pile, en revanche, il libère automatiquement les variables allouées et l'espace de travail de la pile.
Algorithme de résolution de l'accessibilité dans ℤ2 :
Ce projet avait pour cadre l'option algorithme de résolution de problème ou le but était de trouver la solution à un problème donné avec l'algorithme générique vu en cours.
Le problème choisi était celui de l'accessibilité dans le plan entier, soit étant donné un point de départ et d'arrivée ainsi qu'un jeu de vecteur de déplacement, peut-on trouver un chemin allant d'un point à l'autre.
La difficulté de ce problème vient dans le fait que l'algorithme générique parcours l'arbre des points accessibles, ce qui étant donné la taille infini du plan est un problème. Nous avons donc dû déterminer ce qui devait être coupé.
Développement :
Nous avons déterminé deux heuristiques afin de définir cette coupe.
La première consiste à tracer un cercle autour du point d'arrivée et de rayon égal à la distance entre les deux points et la somme des normes des actions puis d'appliquer l'algorithme dans ce cercle. Cela permet en effet de rendre fini l'espace de recherche et donne de bons résultats, mais devient un problème lorsque les points sont éloignés et les actions petites, ce qui donne une complexité temporelle (et spatiale) exponentielle.
La deuxième heuristique a été créé pour régler ce cas particulier, nous avons remarqué que la répétition d'une ou plusieurs actions permettaient de se rapprocher du point d'arrivée. Nous avons donc appliqué une approche géométrique, en traçant un cercle dont le rayon est la somme des normes des actions et le centre le point d'arrivée. Ensuite, pour chaque combinaison d'action, nous regardons si, à partir du point de départ nous pouvions "sauter" dans le cercle d'arrivée où nous appliquerons ensuite l'algorithme générique. Pour calculer la possibilité d'un saut, nous avons juste à calculer l'intersection d'une droite (la combinaison d'action) et d'un cercle. On regarde ensuite si on peut s'arrêter dans cette intersection, soit si en multipliant la combinaison par un entier on atterri dans le cercle.
Cette deuxième heuristique est donc meilleure, mais ne garantit pas la solution, toutefois pour la garantir nous appliquons une dichotomie sur la taille du cercle ce qui fait qu'à un moment, nous aurons un cercle nous ramenant à la première.
Conclusion :
Ce projet fut très instructif. Avec le recul et les nouvelles connaissances apprises en cours d'intelligence artificielle, la construction de ces heuristiques n'a pas été faite de manière optimale et des améliorations pouvaient être possibles. Cependant, nous avions connaissance de meilleures solutions grâce à la littérature, même si ces solutions ne nous étaient pas accessibles de part du corpus de connaissance nécessaire à leur compréhension.
Ce projet s'inscrit dans notre UE d'architecture des ordinateurs servant d'introduction à la programmation très bas niveau et à l'assembleur (ici x86). Le but est de créer un programme en terminal permettant de :
Enregister une personne.
Lister les personnes.
Chercher une personne.
Afficher la personne la plus jeune.
Quitter le programme.
Une personne consiste en un index, un nom et un âge (ex : 1 Zaphod 42).
Développement :
Nous avons fait le choix de stocker les personnes dans un fichier csv.
Nous avons donc commencé par le menu principal consistant en un simple print ainsi que la lecture de l'entrée standard pour connaitre la réponse. Vienne ensuite plusieurs sauts selon le choix :
Pour l'enregistrement, on ouvre le fichier en lecture seule, le parcourront une première fois afin de connaitre son nombre de ligne et où positionner le curseur, puis fermons le fichier avant de l'ouvrir en écriture. Nous écrivons ensuite l'index (en le convertissant en string avec une fonction créée pour l'occasion), lisons puis écrivons le nom puis l'âge en séparant le tout par des virgules et le retour à la ligne à la fin puis fermons le fichier. Si le ficher n'existe pas, il est créé.
Pour lister, nous nous contentons d'ouvrir le fichier en lecture et de le réécrire dans le terminal.
Pour chercher, nous lisons l'entier à chercher dans le terminal puis parcourons le fichier jusqu'à le trouver (ou fin et message d'erreur).
La recherche du plus jeune était plus complexe car pour le trouver nous devons stocker la ligne et l'âge où l'on est ainsi que la ligne et l'âge du plus jeune, tout en gardant les registres nécessaires à la lecture disponibles donc nous les avons stockées dans la pile et la mettons à jour au fur et à mesure du parcours. Il est à noter que l'algorithme utilisé affichera le dernier plus jeune en cas d'égalité.
Nous avons également ajouté une entrée affichant un message d'aide pour l'utilisateur.
Enfin il y a l'option pour quitter le programme qui se contente de faire l'interruption exit.
Toute autre entrée génère un message d'erreur.
Conclusion :
Ce projet nous a permis de correctement appréhender les bases de l'assembleur.
Developpement d'une bibliothèque de gestion d'aéroport :
Ce projet s'inscrit dans le contexte d'un cours de génie logiciel. Le but est de répondre à un cahier des charges simple et de concevoir une architecture avec des pattern appropriés. Ce projet avait aussi pour but l'introduction aux tests et notamment aux tests unitaires.
On se place dans le rôle de développeur pour le compte d'une compagnie aérienne ayant pour but de créer l'aspect métier. Pour cela on a le cahier des charges suivant :
Des compagnies aériennes proposent différents vols.
Un vol a un numéro unique.
Un vol a un jour et une heure de départ et un jour et une heure d’arrivée.
Un vol a un aéroport de départ et un aéroport d’arrivée.
Un vol peut comporter des escales dans des aéroports.
Une escale a une heure d’arrivée et une heure de départ.
Chaque aéroport dessert une ou plusieurs villes.
Un vol est ouvert à la réservation et refermé sur ordre de la compagnie.
Un client peut réserver un ou plusieurs vols, pour des passagers différents.
Une réservation concerne un seul vol et un seul passager.
Une réservation peut être annulée, ou confirmée si elle a été payée.
Ont été ensuite rajouté les vols réguliers. Et la contrainte de ne faire que deux packages.
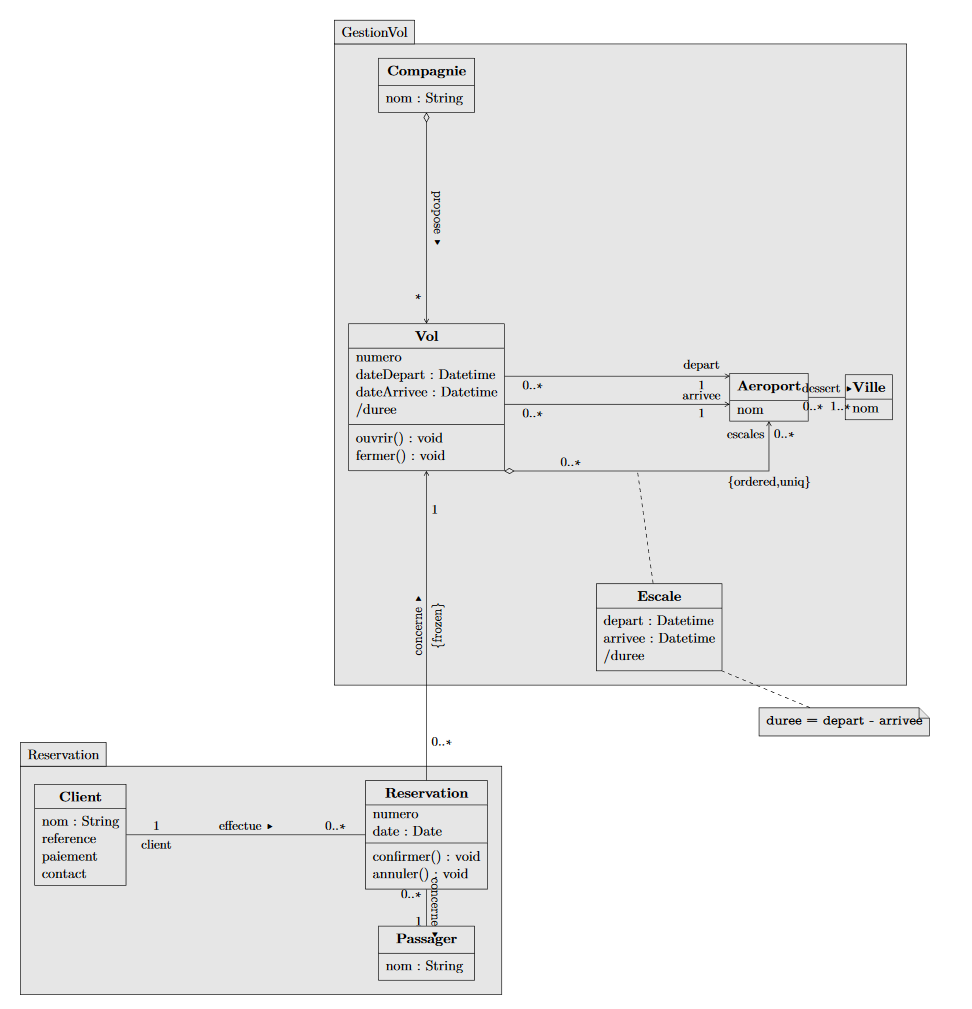
Nous a été donné un diagramme uml simple pour débuter le projet :
Développement :
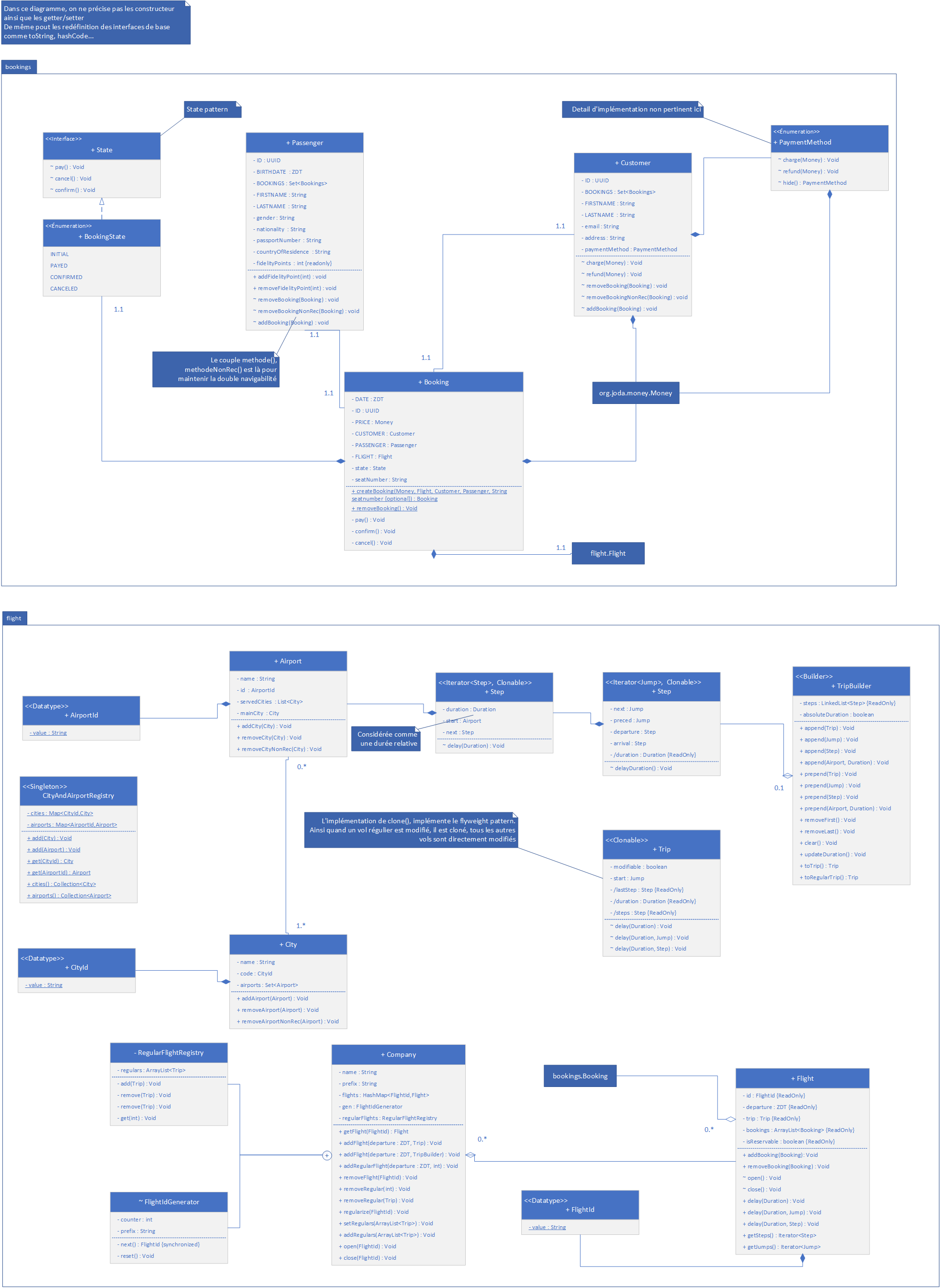
Nous avons choisi pour commencer, de créer plusieurs datatypes pour servir d'identifiant (excepté pour les compagnies). Nous avons choisi l'approche de composition et délégation.
Pour définir un trajet (Trip) nous avons choisi de représenter les temps en vol (Jump) composé d'un aéroport d'arrivée et de départ ainsi que d'une durée (au sol ou en air selon arrivé ou départ) relative (Ce qui nous donne nos escales). Une fois un trajet défini, il suffit de considérer un vol comme un trajet avec une date de départ. Pour simplifier le travail aux prochain développeurs, nous avons exploité le builder pattern et créer une classe TripBuilder.
La classe compagnie est la plus conséquente car elle contient deux classes internes et effectue beaucoup de délégation. Une compagnie est définie par son préfixe et permet de générer des vols grâce à sa classe interne pour créer des identifiant de vol. De plus, chaque compagnie possède des vols réguliers, qui sont en fait de simples trajets stockés dans un registre (la seconde classe interne) et peuvent être utilisés pour créer de nouveaux vols quand nécessaire.
Nous avons également défini les classes ville (City) et aéroport (Airport) en double navigabilité ce qui a compliqué la tâche, notamment pour la suppression de l'un d'entre eux (d'où l'introduction de deux méthodes, l'une prévenant l'autre classe et l'autre non).
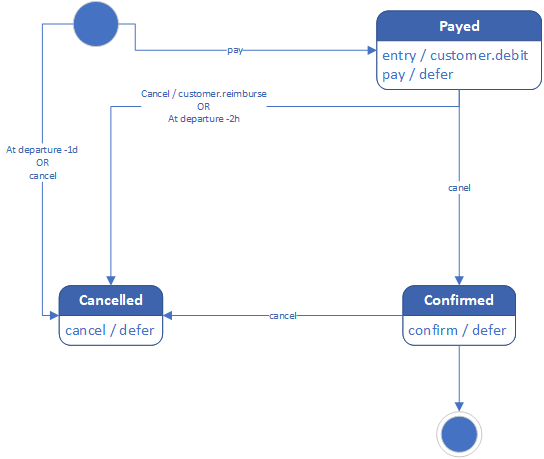
L'autre package concerne les réservations, nous avons commencé par créer les classes client (Customer) et passager (Passenger). Viennent ensuite les réservations, concernant les deux classes précédentes et un vol, cependant, les réservations ont plusieurs états selon le diagramme suivant :
Diagramme d'état des réservations
Pour implémenter cela, nous avons choisi le pattern état, avec l'interface State et avons créé une énumération implémentant cette interface de façon à ce que chaque état soit un singleton. Nous permettant d'économiser de la mémoire.
Cela donne finalement le diagramme simplifié suivant :
Diagramme UML final (simplifié)
En plus de cela il y a le paquet de tests ou sont écrit les tests unitaires pour chaque classe.
Conclusion :
Ce projet nous a permis d'améliorer notre niveau en Java ainsi qu'en outils de compilation. De plus, c'est le premier projet où nous avons utilisé l'outil javadoc afin de générer deux documentations différentes (l'une pour nous et l'autre pour le client). C'est également le premier projet où nous avons utilisé Junit afin de produire des tests unitaires de façon approprié.
Projets en cours :
Ricing Arch Linux :
J'utilise Arch (btw™) avec comme environnement de bureau Hyprland. Je cherche à le personnaliser le plus possible en intégrant de nouveaux outils tout en gérant les compatibilités, et en développant mes propres scripts shell, Python ou Quickshell. Pour les outils plus complexes j'utilise le C, et je développe actuellement mes compétences en Rust pour y contribuer à terme.
Dans le futur je prévois de construire un ordinateur orienté gaming sur Arch Linux en architecture Arm.