This project was part of my M1 internship at the GReD, aimed at simplifying the use of the Biom3d deep learning solution for biologists. The project builds on a study highlighting the lack of reproducibility in deep learning methods for biological imaging, and on Biom3d itself, whose article is currently under publication.
Development:
The work was structured around four axes.
Biom3d maintenance: By analysing the repository with SonarQube, I fixed numerous code issues (unused variables, commented-out code, deprecated numpy random engine) and made error messages more explicit. I also tested the ten models provided in the original publication and found that four were incompatible with the current version. After root cause analysis, the models were fixed and put back on the public repository. I also contributed to the reviewer responses for the scientific article proposing Biom3d, currently under publication, and will be credited as co-author upon its release. Additionally, I greatly extended the documentation to help future developers.
Export to Bio Image Zoo and DeepImageJ: Since DeepImageJ is written in Java and Biom3d in Python, an intermediate format was needed: I chose TorchScript. This required making the entire prediction pipeline compatible, which proved particularly complex: the torchio library used for patch splitting, batch loading, parallelisation and aggregation relies heavily on numpy, which is incompatible with TorchScript. I therefore reimplemented from scratch a compatible GridSampler and GridAggregator, validated by bit-for-bit comparison with the original. I also reimplemented the post-processing filters (keep_big_only, keep_biggest) that depended on skimage. Everything is encapsulated in a new ModelExport module from which exportable models inherit.
Integration into Bacmman: Since Bacmman uses Docker to isolate its deep learning models, the integration was conceptually simpler. I created a Java plugin implementing the DockerDLTrainer interface and a compatible Biom3d Docker image (which required resolving PyTorch/CUDA dependency issues). Training is functional as an MVP; predictions are being integrated, which is proving more difficult due to Bacmman's pipeline system.
Deployment: I also created an embedded Python environment using Conda along with wrapper scripts to build Windows and macOS executables, greatly simplifying installation. I also set up a GitHub CI/CD pipeline to automatically build these executables and Docker images.
Conclusion:
This internship exposed me to varied and concrete technical challenges: cross-language interoperability, TorchScript compiler constraints, GPU dependency management in Docker, and maintaining an existing open source codebase. The main difficulty came from documentation that was often incomplete or contradictory (Bio Image Zoo in particular), which taught me to navigate third-party source code to compensate. The embedded version is already in use at the lab, which is a concrete and satisfying outcome.
REST API for schedule management
Date: February 2025, during my first year of Master's
This project was part of our middleware course, to apply the principles seen in class and gain experience with a language not previously used (Go).
Process :
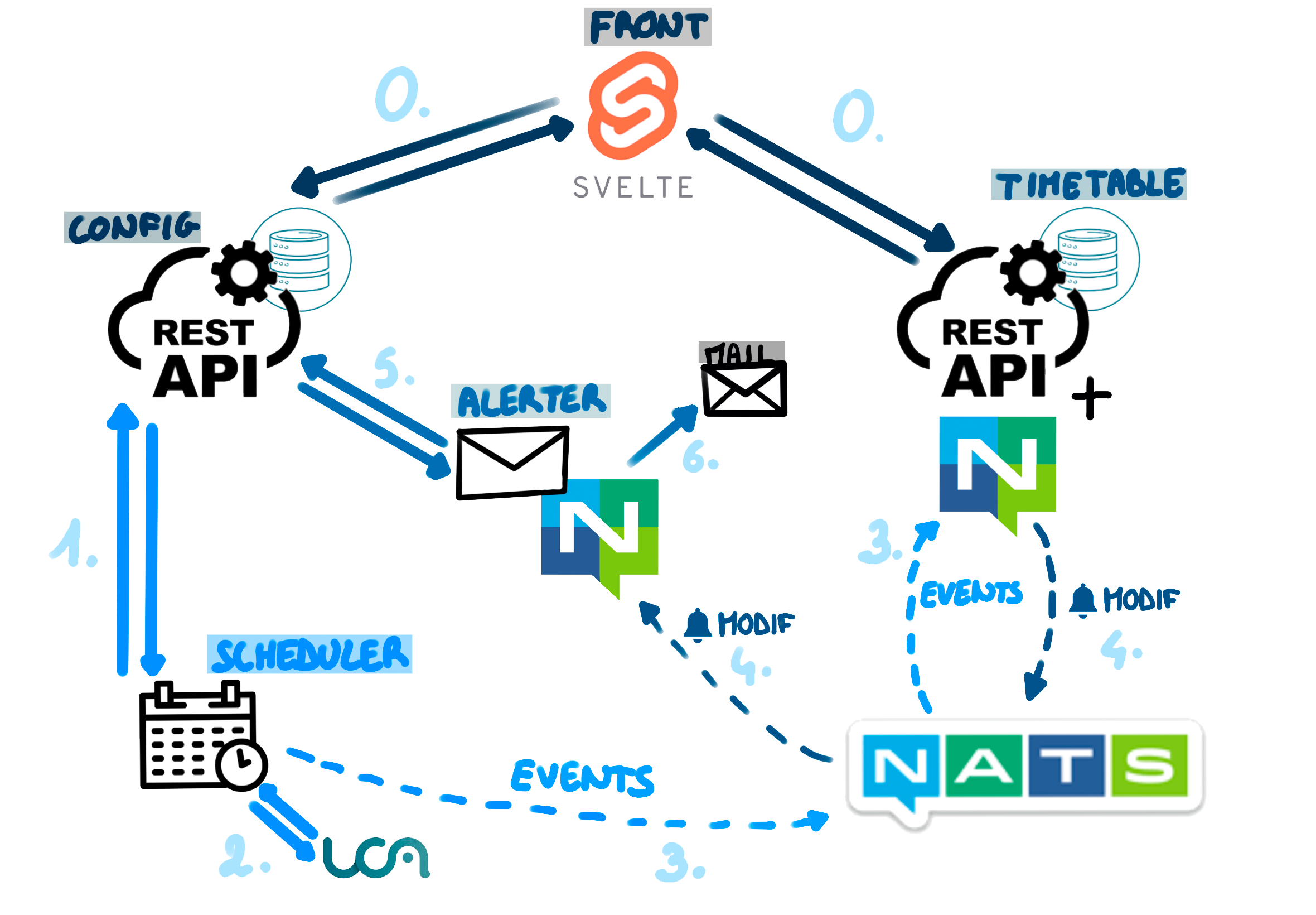
The goal was to create various REST APIs and middleware to reproduce the following diagram:
Diagram of the different middlewares
The frontend was provided, and I was assigned to the Config API. The purpose of this API was to store the schedules followed by the user and to which email to send an alert in case of changes.
I started from a Go project that already defined the GET method and then developed the required HTTP verbs: GET, POST, PUT, DELETE. Additionally, I took the liberty of adding PATCH, OPTIONS, and HEAD. I also wrote the documentation using Swagger. This API reaches level 2 of Richardson's maturity model.
Conclusion :
This project allowed me to learn the basics of Go and to write a complete REST API, which I plan to do again in some personal projects.
DevOps: Continuous deployment of an application
Date: October 2024, during my first year of Master's
Duration: 2 months
Context :
This project was part of our DevOps course. We first completed several labs to become familiar with the different tools (Terraform, Ansible, Docker, Prometheus/Grafana, GitLab CI, Vault), and then independently had to create an infrastructure to continuously deploy several applications.
Process :
The deployment was done on a virtual machine on OpenStack. On this machine, I had to deploy several services:
A WordPress service
A Nextcloud service
A MariaDB database (containing two sub-databases and their users for the first two services)
A Go application (provided on a Git repository), on which I had to include a CI
Expose the above services
The main constraint was that we were allowed only one virtual machine.
To create the virtual machine, I wrote an Ansible script to configure it. This script created the VM, installed the dependencies, and copied the scripts for deploying the other services. A second Ansible script was used to create the OVH records for the three services (the domain names were provided).
To deploy the services, I chose to use Docker, and I deployed them all at once using Docker Compose on the same network. The first service was MariaDB. To create the users, I had to set their passwords. For security reasons, these passwords were stored in Vault and retrieved via a Bash script. The containers for the three applications didn’t cause problems. The main difficulty was exposing the services: for that, I used a Traefik container as the public entry point, accepting only HTTPS connections and redirecting all HTTP traffic to HTTPS. For monitoring, I used Prometheus and Grafana containers. Since Prometheus mainly provided information about the VM and not the other containers, I added a cAdvisor container. However, due to lack of time, I couldn't make a persistent Grafana dashboard.
The CI was the most complex part. It had to install the necessary dependencies, compile the code, build a container, and transmit it to the VM. The containerization was done with a Dockerfile. The most difficult part was the transmission: GitLab only accepted IPv4 connections, while the VM was on IPv6 only (for cost reasons). I first tried using a jumphost, but then preferred that the CI push the Docker image to Docker Hub. This also allowed for better versioning of the application.
Conclusion :
This was by far the most complex project, but also the closest to what would be done in a company, making it very educational. I wasn't able to do everything I wanted, but I managed to produce a satisfying result.
Refactoring Kata:
Date: September 2024, during my first year of Master's
This project was part of our software engineering course. The goal was to get familiar with testing frameworks (JUnit) and refactoring methods. For this, we did a Golden Master on deliberately poorly written code.
Process :
The project was divided into 3 steps:
Writing tests: this part was relatively short, and the difficulty came from the complexity of the code.
Refactoring: this part was the longest and most complex, as I had to determine what needed to be changed (a good part of the code) and find the most appropriate practices and patterns.
Additions: this part was easy, notably because the refactoring made it simpler.
Throughout this project, I used Git to version my work.
Conclusion :
This project allowed me to do tests again and improve in that area, as well as maintain my skills in Java and Git, and strengthen my understanding of software engineering concepts.
This project was part of a course aimed at understanding stochastic simulation, following an exercise where we estimated pi using the Monte Carlo method. The objective was to create a rabbit population simulation with freedom in our design choices. We opted to build a complex simulation by modeling the ecosystem in a simplified way.
Process :
To simulate an ecosystem, we selected four parameters: food, predators, diseases, and climate. Climate is the parameter that most significantly affects the simulation, as it influences the others. Food, predators, and one disease are represented as arrays with mortality rates depending on their index. Diseases are structured as an array with each disease's likelihood of occurrence, as well as two additional arrays with diseases that depend on population density. Finally, climate is divided by month, with each month having a specific humidity level (one of three) and a temperature value (one of three).
There are also parameters related to the rabbits themselves, such as their sex, reproductive ability, and age.
The simulation is then carried out month by month by first calculating mortality, then reproduction, and updating the parameters before moving to the next month. Once the rates are calculated, they are applied to each rabbit in the population. Some parameters work consistently; for example, if the month is humid, young rabbits will have an additional fixed mortality rate due to flooding of the burrows.
The results are then stored in a file summarizing each month. To run a simulation, an initial file with a base rabbit population and an environmental parameters file are required. Several datasets were subsequently created, and statistics were compiled based on the simulation outcomes.
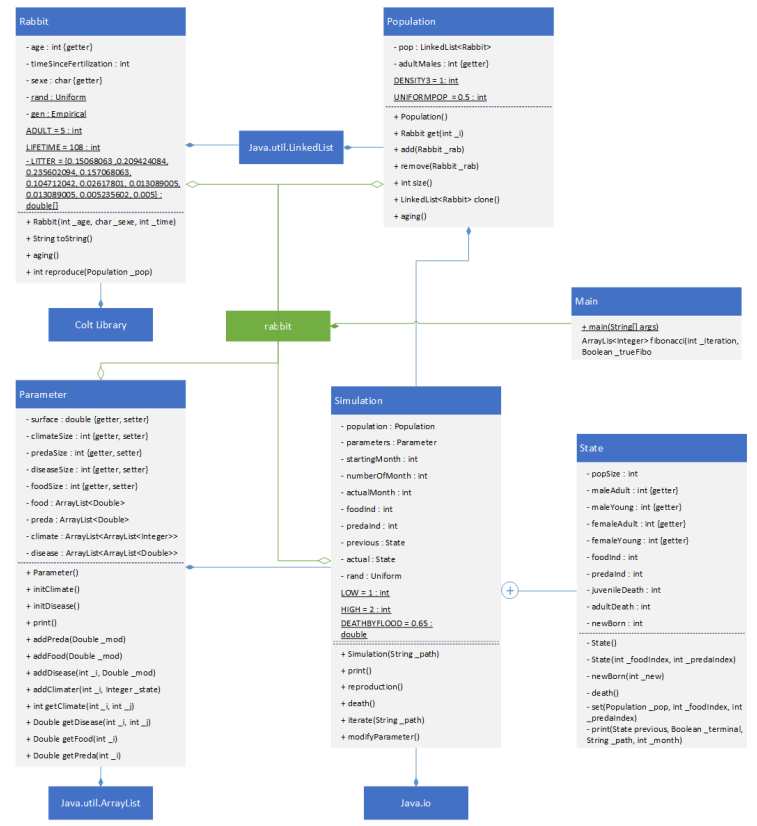
The initial simulation was developed in C, but due to time lost on structure programming and memory management, it was transcribed into Java. Additional reasons supported this choice: Java’s inherent parallelism management and a lack of Java practice that could be addressed through this project.
Uml diagram of the project
Conclusion :
Two conclusions can be drawn regarding the implementation choices : object-oriented principles are minimally adhered to (due to transcription rather than refactoring), and a critical error slipped into the code, the random number generator is initialized within the simulation itself. This causes any looped simulation runs intended to produce varied results for statistical analysis to consistently yield the same outcome.
The datasets were constructed based on intuition and testing, whereas in theory, they should be built from extensive statistical data. As a result, the operations defined on these datasets may not function correctly, or at all, with real data, rendering this simulation invalid. The same applies to certain constants used in the model.
However, modeling a complex system within a much simpler framework was a very interesting and instructive exercise. Additionally, we were able to improve our mastery of certain Java objects (such as lists) and expand our knowledge of rabbit biology (even though this wasn’t the project’s main objective).
This project was part of a web course, following a frontend project (which I am not presenting here as it is less interesting, and this site is equally representative). The objective was to introduce us to backend development using Java Spark while avoiding other frameworks to better understand the underlying mechanics. We chose the Pokemon theme to gain access to the PokeAPI, allowing us to focus on the backend. This project was also the first where we used Gradle.
The goal is to meet the following specifications :
A user can create an account and log in.
A user can trade Pokemon with other user.
A user can level up a Pokemon (his or not) 5 times a day.
A user earns a Pokemon on his first daily log in.
We were also required to use the Model-View-Controller (MVC) pattern, as well as create and manage the database necessary for our application. Additionally, we had to use the FreeMarker technology to generate the web pages.
Process :
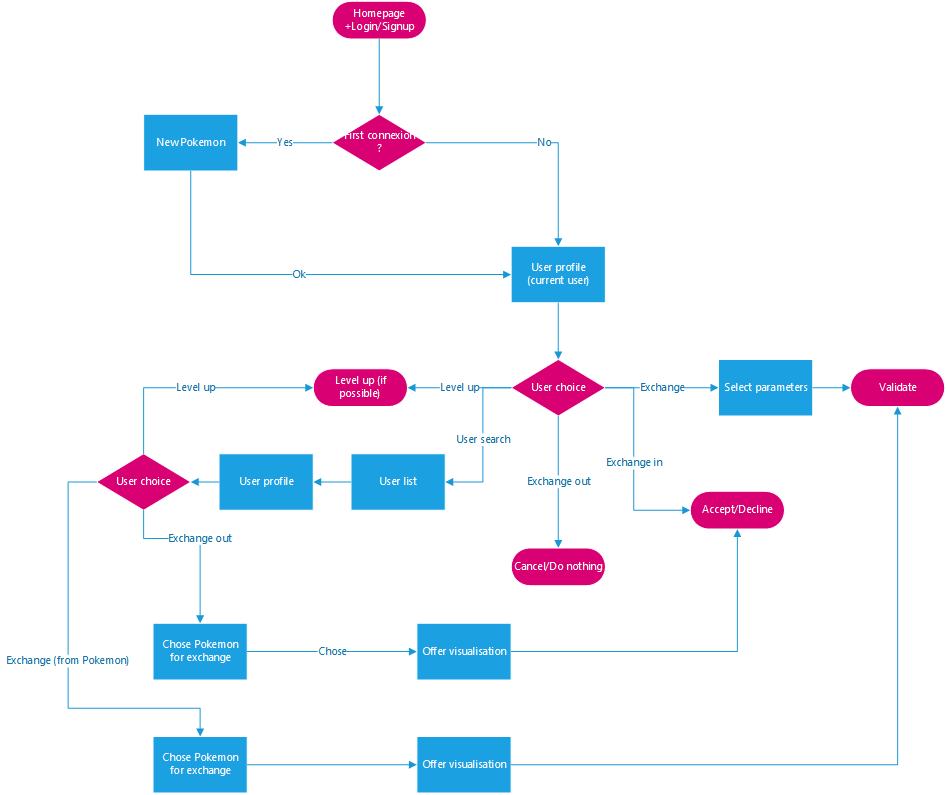
We defined the following flow :
Flow diagram
Each user can access 6 pages :
Their profile.
Other user's profile.
A Pokemon page.
Their outgoing exchange page (the ones they offers).
Teir incoming exchange page (the request they receives).
The outgoing exchange page of other users.
As well as other intermediary pages, such as those that allow the creation of an exchange or the page that provides a Pokemon upon first login.
The page templates were created with FreeMarker and use static CSS pages; they contain only the bare minimum, as the goal was not to create a visually appealing website but to focus on the backend.
Conclusion :
There are several criticisms that can be directed at this project. Firstly, Java is sometimes misused, particularly with special cases that could be replaced by exceptions. Additionally, password security was not optimal because the salt was stored in the same database as the application. Furthermore, the site operates over unsecured HTTP, as self-certification was an unfamiliar concept for us at that time.
The database also shouldn't be used in production as it is primarily a development database (notably with minimal constraints).
Additionally, there remains a bug in the application where a player can trade with themselves, resulting in the deletion of all existing exchanges for the Pokemon involved (as in the case of a trade with another player, it makes sense to remove other exchanges since they become irrelevant).
This project was part of the compilation course, specifically advanced language theory, where it was included in the evaluation. The objective was to create a compiler for the MVAP virtual machine (as it has simple instructions).
We were required to use ANTLR to create this compiler.
Process :
There is little to say about the implementation and choices, as it simply involves transcribing the grammar provided in the assignment. For the implementation of the tools used by the language (calculation of GCD and LCM) or variables used for loops, we allocated memory space at the beginning of the stack (since it is the only known location at compile time). Additionally, variables must be declared at the start of the program because they are also added at the beginning of the stack.
Several additions were made compared to the assignment. Firstly, we added comments with the same syntax as in C. In addition to the do-while loop requested in the assignment, we also included the while loop, as well as increment and decrement operators for integer variables, allowing for the creation of the for loop.
Conclusion :
One of the features we attempted to implement does not work. Indeed, we wanted the compiler to add an instruction to clear the stack created in the program. However, the "non-deterministic" nature of conditions and loops prevented the calculation of the stack size. On the other hand, it automatically frees the allocated variables and the working space of the stack.
This project was part of the problem-solving algorithms option, where the goal was to find a solution to a given problem using the generic algorithm discussed in class.
The chosen problem was that of accessibility in the integer plane, which involves determining whether a path can be found from a given starting point to a destination point, given a set of movement vectors.
The difficulty of this problem arises from the fact that the generic algorithm traverses the tree of accessible points, which, given the infinite size of the plane, presents a significant challenge. Therefore, we had to determine what should be cut off.
Process :
We established two heuristics to define this cutoff.
The first heuristic involves drawing a circle around the destination point, with a radius equal to the distance between the two points and the sum of the norms of the actions, and then applying the algorithm within this circle. This effectively makes the search space finite and yields good results. However, it becomes problematic when the points are far apart and the actions are small, leading to exponential time (and space) complexity.
The second heuristic was created to address this particular case. We noticed that repeating one or more actions allowed us to get closer to the destination point. Therefore, we applied a geometric approach by drawing a circle with a radius equal to the sum of the norms of the actions and centered at the destination point. Next, for each combination of actions, we check whether we could "jump" into the arrival circle from the starting point, where we would then apply the generic algorithm. To calculate the possibility of a jump, we only need to calculate the intersection of a line (the combination of actions) and a circle. We then check if we can stop within this intersection, meaning that by multiplying the combination by an integer, we land in the circle.
This second heuristic is therefore better, but it does not guarantee a solution. However, to ensure a solution, we apply a dichotomy on the size of the circle, which means that at some point, we will have a circle that leads us back to the first heuristic.
Conclusion :
This project was very instructive. In hindsight, with the new knowledge gained in artificial intelligence classes, the construction of these heuristics was not done optimally, and improvements could be made. However, we were aware of better solutions available in the literature, even though these solutions were not accessible to us due to the necessary knowledge corpus required for their understanding.
This project is part of our Computer Architecture course, serving as an introduction to low-level programming and assembly (specifically x86). The goal is to create a terminal program that allows for:
Register a person.
List persons.
Search a person.
Print the youngest person.
Quit the program.
A person consists of an index, a name, and an age (e.g., 1 Zaphod 42).
Process :
We chose to store the persons in a CSV file.
We then started with the main menu, consisting of a simple print statement and reading from the standard input to determine the response. Next, several jumps follow based on the choice :
For the registration, we open the file in read-only mode and traverse it once to determine the number of lines and where to position the cursor. We then close the file before opening it in write mode. We write the index (converting it to a string with a function created for this purpose), read and write the name, then the age, separating everything with commas and adding a newline at the end before closing the file. If the file does not exist, it is created.
To list, we simply open the file in read mode and rewrite its contents in the terminal.
To search, we read the integer to look for from the terminal, then we traverse the file until we find it (or reach the end, displaying an error message).
The search for the youngest person was more complex because to find them, we needed to store both the current line and age as well as the line and age of the youngest found so far. To keep the necessary registers available for reading, we stored these in the stack and updated them as we traversed the file. It is worth noting that the algorithm used will display the last youngest person in case of a tie.
We also added an entry displaying a help message for the user.
Finally, there is the option to exit the program, which simply triggers the exit interrupt.
Any other input generates an error message.
Conclusion :
This project allowed us to properly understand the basics of assembly language.
This project is part of a software engineering course. The goal is to meet a simple set of specifications and to design an architecture with appropriate patterns. This project also aimed to introduce testing, particularly unit testing.
We take on the role of a developer for an airline company tasked with creating the business aspect. For this, we have the following specifications:
Airlines offer different flights.
A flight has a unique number.
A flight has a departure day and time, as well as an arrival day and time.
A flight has a departure airport and an arrival airport.
A flight can have layovers at airports.
A layover has an arrival time and a departure time.
Each airport serves one or more cities.
A flight is open for booking and can be closed at the airline's request.
A customer can book one or more flights for different passengers.
A reservation concerns a single flight and a single passenger.
A reservation can be canceled or confirmed if it has been paid.
Regular flights were then added, along with the constraint of having only two packages.
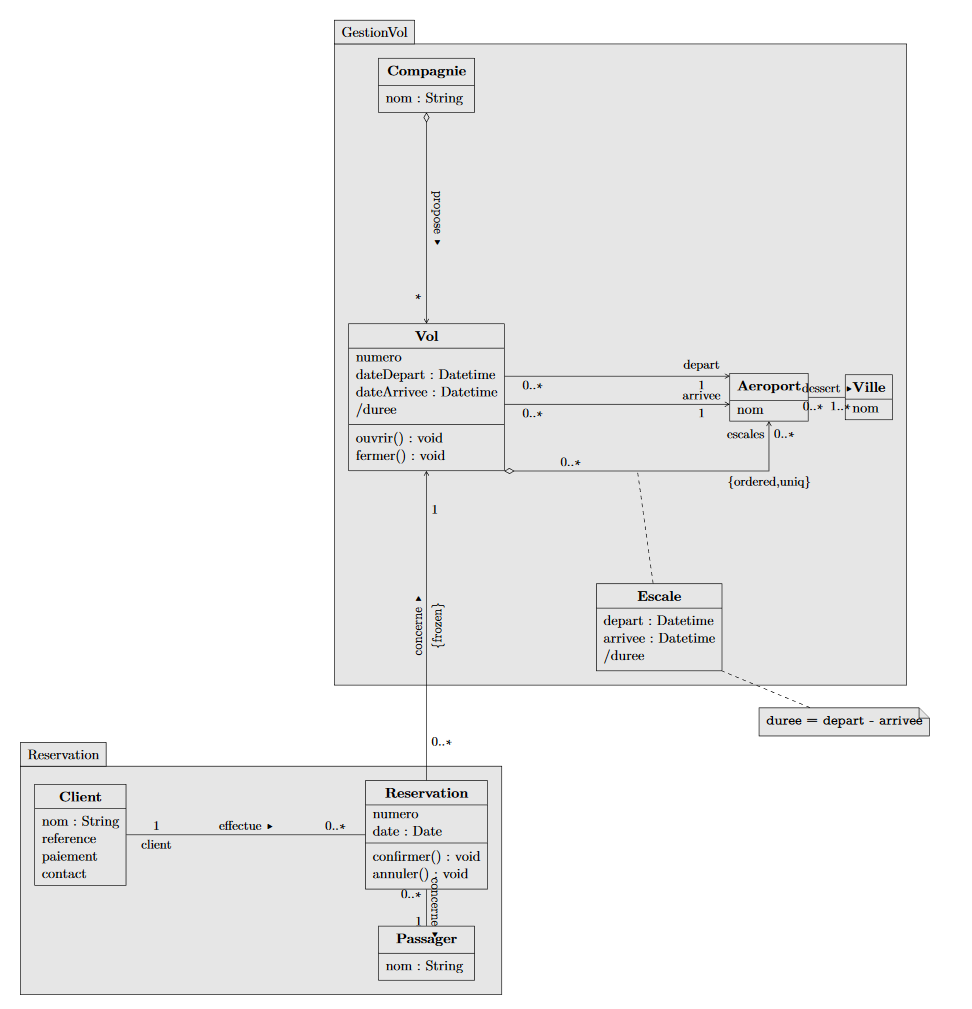
Nous a été donné un diagramme uml simple pour débuter le projet :
Process :
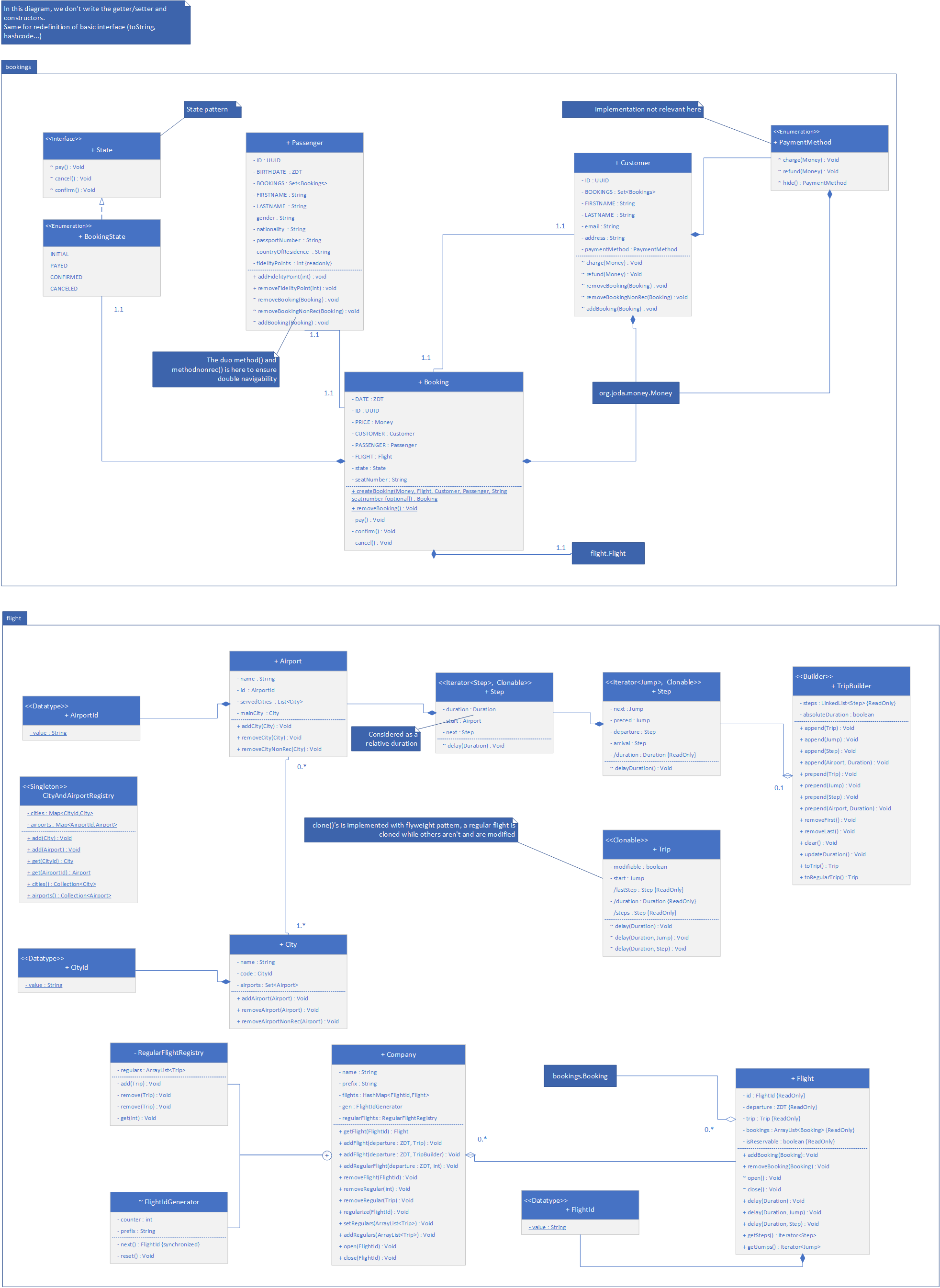
We initially chose to create several data types to serve as identifiers (except for the companies). We opted for a composition and delegation approach.
To define a trip (Trip), we chose to represent the flight times (Jump) as consisting of a departure and arrival airport, as well as a duration (on the ground or in the air, depending on whether it’s arrival or departure) relative to each other (which gives us our layovers). Once a trip is defined, a flight can simply be considered as a trip with a departure date. To simplify the work for future developers, we utilized the builder pattern and created a TripBuilder class.
The Airline class is the most substantial because it contains two internal classes and performs a lot of delegation. An airline is defined by its prefix and allows for the generation of flights through its internal class to create flight identifiers. Additionally, each airline has regular flights, which are essentially simple trips stored in a registry (the second internal class) and can be used to create new flights when necessary.
We also defined the City and Airport classes with bidirectional navigation, which complicated the task, especially when it came to deleting one of them (hence the introduction of two methods: one notifying the other class and the other not).
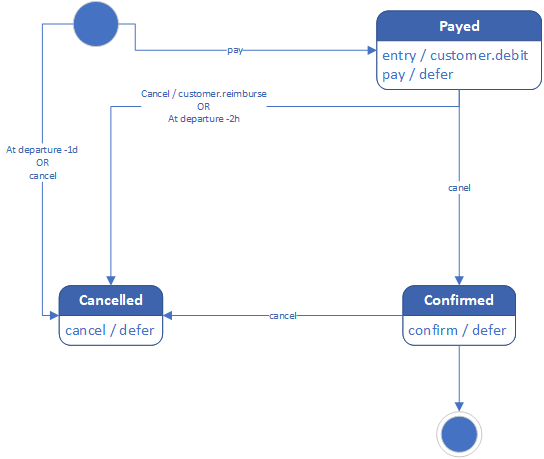
The other package concerns reservations. We started by creating the Customer and Passenger classes. Then come the reservations, which involve the two previous classes and a flight. However, reservations have several states according to the following diagram:
Booking's state diagram
To implement this, we chose the State pattern, with the State interface, and created an enumeration implementing this interface so that each state is a singleton. This allows us to save memory.
This ultimately results in the following simplified diagram :
Simplified UML diagram
In addition to that, there is the test package where unit tests are written for each class.
Conclusion :
This project allowed us to improve our skills in Java as well as in compilation tools. Moreover, it is the first project where we used the Javadoc tool to generate two different documentations (one for us and the other for the client). It is also the first project where we used JUnit to produce unit tests appropriately. Some conditional test could have been replaced by assertions that we learned after.
Current projects:
Arch Linux ricing:
I use Arch (btw™) with Hyprland as my desktop environment. I aim to customise it as much as possible by integrating new tools while managing compatibility, and by writing my own shell, Python or Quickshell scripts. For more complex tools I use C, and I am currently developing my Rust skills to contribute to that ecosystem in time.